Sobre bases de datos, hace muchos años que tengo pendiente escribir algo del Modelo de Conjuntos Anidados (The Nested Set Model) como forma de guardar una estructura de árbol en la tabla de una base de datos relacional. Uno uso práctico habitual es guardar un menú de opciones. Antes de ello, mejor introducir la relación reflexiva (o recursiva) de una tabla consigo misma.
En una tabla así, uno de sus campos hace referencia a la clave primaria, de tal modo que puede establecerse una relación de jerarquía. Es recomendable crear un clave foránea que apunte desde ese campo a la clave primaria. A continuación, veamos un ejemplo en el que el campo «cap» (jefe) de la tabla de empleados apunta al identificador del empleado:
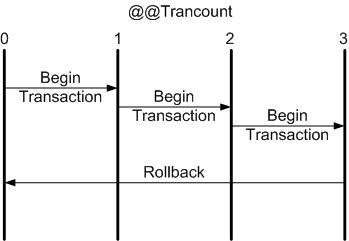
Este es su conjunto de datos para el ejemplo:
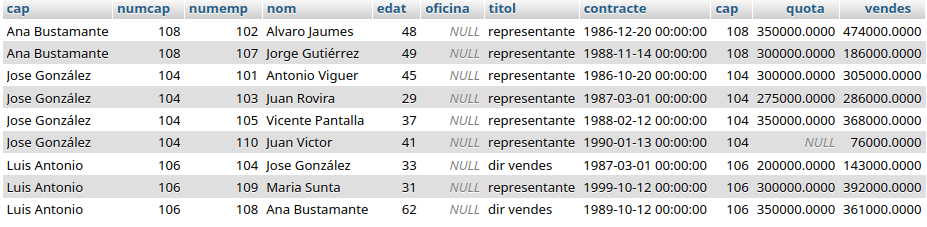
Esta consulta devuelve los jefes, mostrando su nombre y número de empleado, y los empleados que tiene cada uno. De los empleados muestra todos sus atributos (e.* hace referencia a todos los campos de la tabla):
SELECT c.nom as cap, c.numemp as numcap, e.*
FROM empleats AS c JOIN empleats AS e ON c.numemp = e.cap
ORDER BY c.nom;
Debe prestarse atención en el orden en el que aparecen los campos para hacer el join, si se intercambian de este modo:
SELECT c.nom AS cap, c.numemp AS numcap, e.*
FROM empleats AS c LEFT JOIN empleats AS e ON c.cap = e.numemp
ORDER BY c.nom;
La tortilla se ha girado, el SELECT no da la misma información que antes, pues ahora los campos «e» representan los jefes:
Para obtener los jefes y sus empleados, tal y como estamos haciendo desde el principio, la siguiente consulta con LEFT JOIN no da lo buscado:
SELECT c.nom as cap, c.numemp as numcap, e.*
FROM empleats AS c LEFT JOIN empleats AS e ON c.numemp = e.cap
ORDER BY c.nom;
La que se ha solicitado aquí es tratar a todos los empleados como jefes, si lo son se mostrarán sus empleados; en el caso de ser empleados «rasos» todos los atributos de su empleado aparecen nulos, pues carecen de los mismos.
Ahora bien, esto no significa que una consulta OUTER, LEFT o RIGHT, no pueda ser útil en una relación reflexiva. Por ejemplo, si se desea un listado de todos los empleados y su jefe al lado, debe emplearse un OUTER para conseguir que también aparezcan los empleados sin jefe directo, como es el caso del director general:
SELECT e.nom as empleat, e.numemp as numempleat, c.*
FROM empleats AS e LEFT JOIN empleats AS c ON c.numemp = e.cap
ORDER BY c.nom;
La nueva generación de javascripters cree que inventó justo ayer la programación web, pero resulta que hace 25 años ya se libraba la misma batalla que libran ahora, sólo que exclusivamente con LAMP. A Docker y Kubernetes no se llegó precisamente de sopetón… La solución a los problemas fue aumentar la complejidad, lo que a su vez creó nuevos problemas, esta situación y su evolución se describe en este breve artículo de Ben Johnson de lectura muy recomendable.
Asimismo, propone una solución en la que se deshace gran parte de la complejidad añadida durante más de 2 décadas. Esta solución consiste en aumentar la capacidad de un servidor en vez de aumentar el número de los mismos y emplear… ¡el denostado SQLite! (Al menos denostado para las aplicaciones web) Hoy en día Amazon, a través de AWS, ofrece servidores con 96 núcleos y cientos de gigas de RAM. En un servidor bastante más grande, pero dentro de lo que puede administrar un kernel de Linux, se ha conseguido con SQLite la friolera de 4 millones de consultas SQL por segundo con un solo hilo.
El inconveniente de SQLite, es que a diferencia de los sistemas gestores de bases de datos relacionales como MySQL u Oracle, no tiene capacidades de red, con lo que no hay replicación de los datos a otros servidores, entre otros inconvenientes, por lo que si el servidor revienta, se perdieron los datos desde la última copia de seguridad realizada. Para solucionar este problema, Ben ha creado Litestream, una herramienta que se encarga de replicar continuamente una base de datos SQLite en un Amazon S3 (un servicio de almacenamiento en la nube).
Curiosa e interesante iniciativa, que lleva el principio KISS (Keep it simple, stupid!) al extremo. A ver cómo evoluciona…
Las instrucciones SQL de manipulación de datos o DML (Data Manipulation Language) pueden producir una grave pérdida o alteración de los datos. Un descuido en la sintaxis al escribir una orden UPDATE, por ejemplo, o cualquier otro «detalle» que pase desapercibido en ese momento pueden tener unas consecuencias completamente indeseadas para los valiosos datos. Para evitar caer en esa situación, existen dos posibilidades que no son mutuamente excluyentes. La primera, la más evidente, usar la instrucción por excelencia del DQL (Data Query Language):
SELECT
En un caso hipotético, se desea concatenar los campos del piso (adfloor) y el número (adnumber) a la dirección (address) como paso previo a la eliminación de estos. Un SELECT que adelante los resultados del UPDATE sería:
SELECT address, adnumber, adfloor,
concat(coalesce(address, ''), ' ', coalesce(adnumber, ''), ' ', coalesce(adfloor, '')) AS address_concat
FROM table;
Si los resultados son los esperados, puede lanzarse el UPDATE:
Cuando estamos alterando la estructura de un tabla en MySQL, nos podemos encontrar con el siguiente error al añadir una llave foránea:
MySQL Cannot Add Foreign Key Constraint
Estos errores con poca información son más molestos de lo habitual. Como las posibles razones por las que el motor de la base de datos no ha podido crearla son diversas, sería ventajoso evitar tener que estudiarlas una por una. Esto lo podemos lograr con la siguiente orden:
SHOW ENGINE INNODB STATUS;
En la sección «LATEST FOREIGN KEY ERROR» encontraremos una descripción del error más completa.
| InnoDB | |
=====================================
2018-02-20 11:22:34 0x7f075c175700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 25 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 12622 srv_active, 0 srv_shutdown, 5333759 srv_idle
srv_master_thread log flush and writes: 5344820
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 19660
OS WAIT ARRAY INFO: signal count 17755
RW-shared spins 0, rounds 11780, OS waits 6140
RW-excl spins 0, rounds 17899, OS waits 382
RW-sx spins 738, rounds 11751, OS waits 121
Spin rounds per wait: 11780.00 RW-shared, 17899.00 RW-excl, 15.92 RW-sx ------------------------
LATEST FOREIGN KEY ERROR
------------------------
2018-02-19 09:36:53 0x7f075c208700 Cannot drop table `serca`.`promo_landing`
because it is referenced by `serca`.`promo_landing_i18n`
------------
TRANSACTIONS
------------
Trx id counter 1864352
Purge done for trx's n:o < 1864352 undo n:o < 0 state: running but idle
History list length 808
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421144897607520, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
310347 OS file reads, 83964 OS file writes, 23539 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.92 writes/s, 0.52 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 7 merges
merged operations:
insert 4, delete mark 3, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34673, node heap has 2 buffer(s)
Hash table size 34673, node heap has 14 buffer(s)
Hash table size 34673, node heap has 3 buffer(s)
Hash table size 34673, node heap has 35 buffer(s)
Hash table size 34673, node heap has 8 buffer(s)
Hash table size 34673, node heap has 9 buffer(s)
Hash table size 34673, node heap has 4 buffer(s)
Hash table size 34673, node heap has 2 buffer(s)
11.56 hash searches/s, 1.68 non-hash searches/s
---
LOG
---
Log sequence number 567281250
Log flushed up to 567281250
Pages flushed up to 567281250
Last checkpoint at 567281241
0 pending log flushes, 0 pending chkp writes
15014 log i/o's done, 0.28 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 42107376
Buffer pool size 8191
Free buffers 1024
Database pages 7090
Old database pages 2597
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 150106, not young 4595614
0.16 youngs/s, 0.00 non-youngs/s
Pages read 308306, created 2548, written 65550
0.00 reads/s, 0.00 creates/s, 0.60 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 7090, unzip_LRU len: 0
I/O sum[18]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=1022, Main thread ID=139669620905728, state: sleeping
Number of rows inserted 12470971, updated 1849, deleted 367, read 104405344
0.24 inserts/s, 0.00 updates/s, 0.00 deletes/s, 2852.41 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
Como excusa para probar Simple Screen Recorder en mi portátil, he hecho el siguiente vídeo en el que explico lo mismo:
PDO, acrónimo de PHP Data Objects es un interfaz para acceder a bases de datos desde PHP. A diferencia de las extensiones mysql y mysqli, que son exclusivas para MySQL, PDO puede trabajar con diferentes sistemas gestores de bases de datos, siempre y cuando haya driver para el mismo.
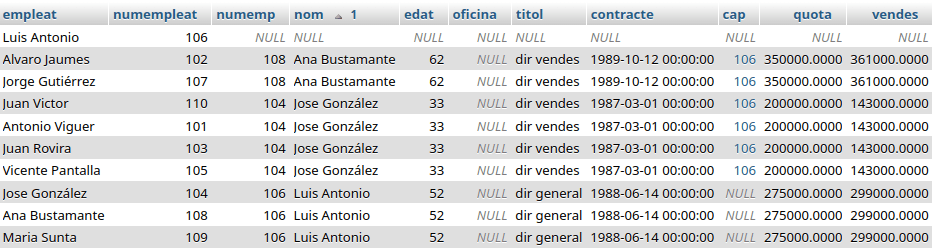
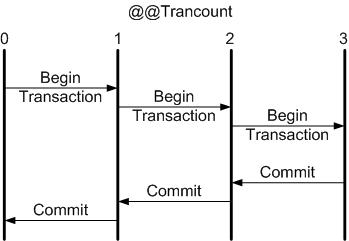
Las transacciones sirven para garantizar la integridad referencial de los datos. Una transacción está formada por varias órdenes SQL y bien se ejecutan todas las consultas en bloque o si alguna falla se vuelve al estado inicial antes de empezar la transacción, sin ejecutarse ninguna de ellas. Las transacciones deben cumplir con las propiedades ACID: Atomicidad, Consistencia, Isolation (aislamiento) y Durabilidad. (Nada que ver con el subgénero de música electrónica de finales de los 80 🙂 )
Las transacciones se anidan cuando existiendo una transacción en curso, se inicia otra. Esto por ejemplo sucede cuando desde un método donde se ha iniciado una transacción, para reciclar código (una de las virtudes de la programación orientada a objetos) se llama a otro método que inicia otra transacción.
Todo fue bien hasta el final y se ejecutan en bloque todas las transacciones (COMMIT)
¡Ups, algo fallo cuando ya casi finalizaba! ¡Déjalo todo como estaba! (ROLLBACK)
Desgraciadamente, desarrollando en LAMP, nada más iniciarse la segunda transacción se producirá un error fatal. MySQL no soporta las transacciones anidadas. En su documentación afirma que después de ejecutarse un BEGIN TRANSACTION ciertas órdenes producirán un COMMIT, entre ellas BEGIN TRANSACTION. Tampoco las soporta PostgreSQL. Una solución parcial que ambos sistemas incorporan son los SAVE POINTS.
A continuación viene el esquema de una clase que mediante los SAVE POINTS y controlando el número de transacciones anidadas mediante la propiedad transactionDepth, consigue algo parecido a anidar transacciones y por lo tanto evita el error fatal antes mencionado.
Si tu clase extiende la clase PDO, el método execute puede ser reemplazado llamando simplemente a $this->exec() Como digo, esta clase es un esquema para entender la idea, no está pensada para funcionar directamente sino que el programador interesado en ella deberá adaptarla.
class Db {
static private $instance = null;
static private $connection = null;
protected $transactionDepth = 0;
private function __construct() {
}
private function _connect() {
if (self::$connection === null) {
try {
/* Código para conectarse a la BD */
self::$connection = new PDO('mysql:host=localhost', 'root', 'root');
} catch (PDOException $e) {
echo "error pdo: " . $e->getMessage();
}
}
return self::$connection;
}
/* Nada que clonar en el patrón de diseño Singleton */
private function __clone()
{
}
static public function getInstance()
{
if (is_null(self::$instance)) {
self::$instance = new self();
}
return self::$instance;
}
static public function closeConnection()
{
self::$instance = null;
if (isset(self::$connection)) {
self::$connection = null;
}
}
public function getConnection()
{
return $this->_connect();
}
protected function prepare($query, $params = array())
{
$stmt = $this->getConnection()->prepare($query);
if (is_array($params)) {
foreach ($params as $param => $value) {
if (is_bool($value)) {
$type = PDO::PARAM_BOOL;
} elseif ($value === null) {
$type = PDO::PARAM_NULL;
} elseif (is_integer($value)) {
$type = PDO::PARAM_INT;
} else {
$type = PDO::PARAM_STR;
}
$stmt->bindValue(":$param", $value, $type);
}
}
return $stmt;
}
public function execute($sql, $params = array())
{
$stmt = $this->prepare($sql, $params);
$stmt->execute();
$stmt->closeCursor();
return $stmt->rowCount();
}
public function begin()
{
if ($this->transactionDepth === 0) {
$this->getConnection()->beginTransaction();
}else{
$this->execute("SAVEPOINT LEVEL{$this->transactionDepth}");
}
$this->transactionDepth++;
}
public function commit()
{
$this->transactionDepth--;
if ($this->transactionDepth === 0) {
return $this->getConnection()->commit();
}else{
return $this->execute("RELEASE SAVEPOINT LEVEL{$this->transactionDepth}");
}
}
public function rollback()
{
if ($this->transactionDepth === 0) {
throw new LogicException("Ninguna transacción en curso para retroceder");
}
$this->transactionDepth--;
if ($this->transactionDepth === 0) {
return $this->getConnection()->rollback();
}else{
return $this->execute("ROLLBACK TO SAVEPOINT LEVEL{$this->transactionDepth}");
}
}
}
Las bases de datos relacionales (Oracle, SQL Server, Access, MySQL, etc) están basadas en el álgebra relacional. Dicha álgebra la desarrolló el ingeniero británico Edgar F. Codd en 1970 mientras trabajaba para IBM, pero el gigante azul tardó en desarrollar su primera base de datos relacional por preferir seguir explotando los ingresos de su base de datos IMS/DB. Mientras IBM se dedicaba a rentabilizar al máximo su inversión, otras empresas se llevaron el gato al agua al desarrollar sus propios sistemas relacionales a partir de los papeles de Codd. Habían cambiado para siempre las bases de datos.
Codd proporcionó las bases teóricas para las bases de datos relacionales y para los lenguajes que las manipulan. El rey de estos lenguajes es SQL, Structured Query Language. Ahora bien, lo llamo rey por lo extendido que está desde hace décadas, pues curiosamente tiene una carencia importante muy llamativa: no implementa el antijoin que define los papeles de Codd, sin que aparentemente tenga ninguna dificultad su implementación.
Si definimos el semijjoin (el left o right join de siempre) entre dos tablas A y B como:
Es decir, el left semijoin de las tablas A y B es la unión de todos los elementos a que pertenezcan a A junto con al menos uno de b que pertenezca/n a B y que satisfagan una función sobre a U b. Esta función hace referencia al campo o campos de ambas tablas que hacemos servir para el join, usando sintaxis de MySQL sería
FROM A LEFT JOIN B ON (A.id = B.id)
El antijoin se definiría así:
Es decir, el antijoin de las tablas A y B es la unión de todos los elementos que satisfacen la función sobre a U ba que pertenezcan a A y no pertenezcan a B.
Desgraciadamente SQL no dispone de algo como:
FROM A ANTI JOIN B ON (A.id = B.id)
Y toca ir haciendo apaños como:
FROM A
WHERE A.id NOT IN(
SELECT id
FROM B)
O la supuesta optimización:
FROM A
LEFT JOIN B ON A.id = B.id
WHERE B.id IS NULL
Que producirá resultados inesperados si el campo pivote es nulo en algún registro de B.
Personalmente no veo que sea técnicamente más complicado implementar en los sistemas gestores de bases de datos un antijoin que otros tipos de join, pero el hecho es que de momento ninguno de los sistemas más extendidos lo incorpora en su dialecto SQL.
Editado el 22/01/2020:
En la última versión de MySQL, la 8.0.17, se va a optimizar el «apaño» antes explicado traduciendo la cláusula IN internamente como ANTIJOIN, según se comenta en la documentación. Podemos encontrar más información aquí.


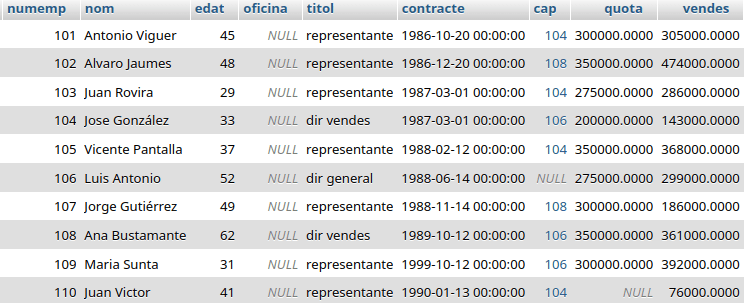
 Debe prestarse atención en el orden en el que aparecen los campos para hacer el join, si se intercambian de este modo:
Debe prestarse atención en el orden en el que aparecen los campos para hacer el join, si se intercambian de este modo: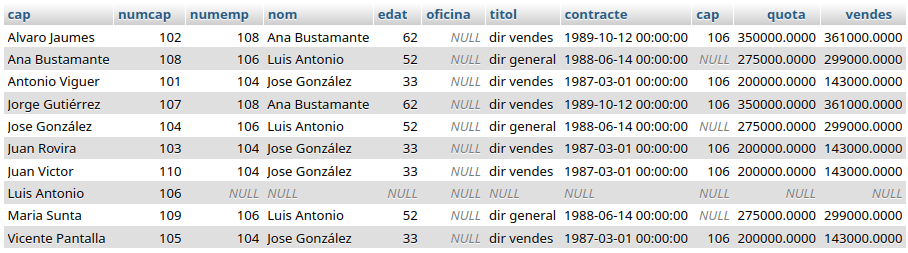
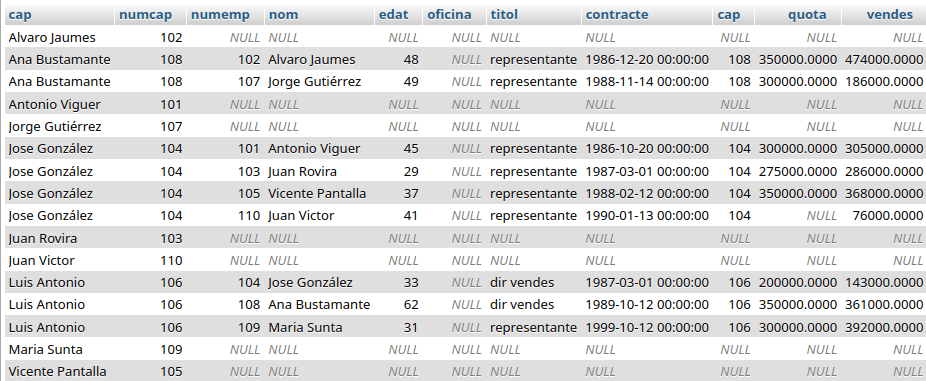 La que se ha solicitado aquí es tratar a todos los empleados como jefes, si lo son se mostrarán sus empleados; en el caso de ser empleados «rasos» todos los atributos de su empleado aparecen nulos, pues carecen de los mismos.
La que se ha solicitado aquí es tratar a todos los empleados como jefes, si lo son se mostrarán sus empleados; en el caso de ser empleados «rasos» todos los atributos de su empleado aparecen nulos, pues carecen de los mismos.