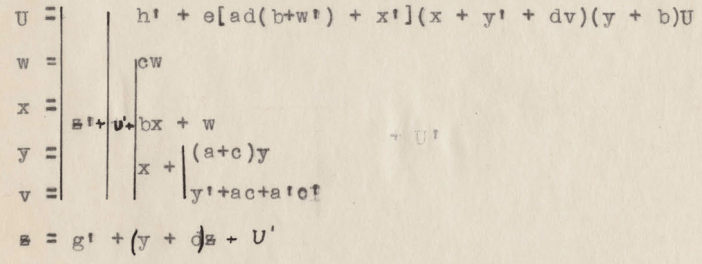Sobre bases de datos, hace muchos años que tengo pendiente escribir algo del Modelo de Conjuntos Anidados (The Nested Set Model) como forma de guardar una estructura de árbol en la tabla de una base de datos relacional. Uno uso práctico habitual es guardar un menú de opciones. Antes de ello, mejor introducir la relación reflexiva (o recursiva) de una tabla consigo misma.
En una tabla así, uno de sus campos hace referencia a la clave primaria, de tal modo que puede establecerse una relación de jerarquía. Es recomendable crear un clave foránea que apunte desde ese campo a la clave primaria. A continuación, veamos un ejemplo en el que el campo «cap» (jefe) de la tabla de empleados apunta al identificador del empleado:
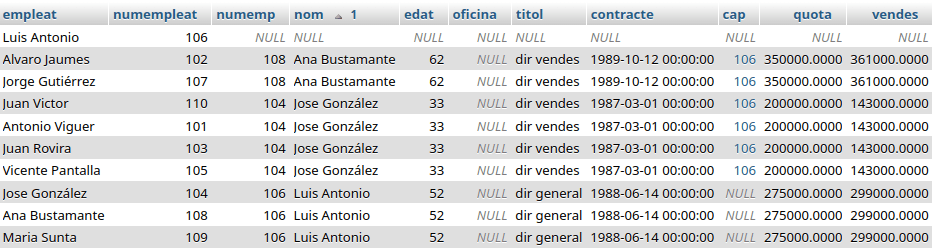
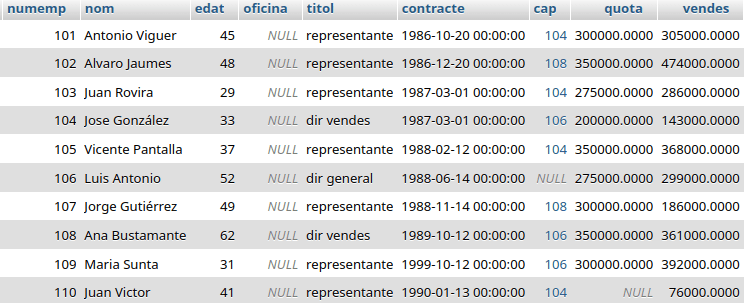
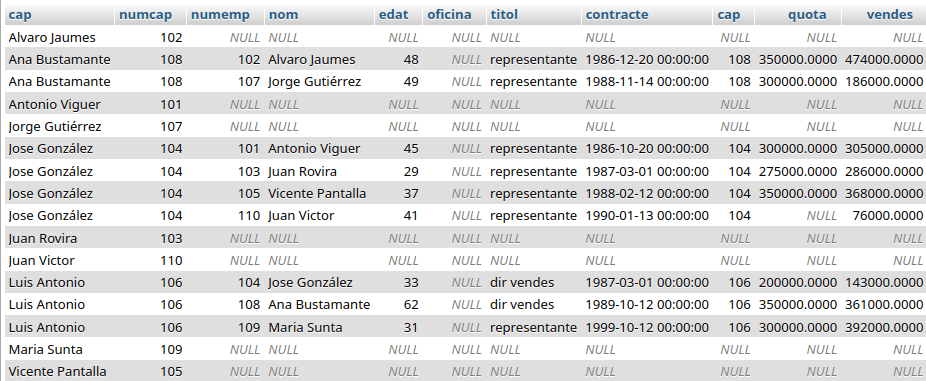
Este es su conjunto de datos para el ejemplo:
Esta consulta devuelve los jefes, mostrando su nombre y número de empleado, y los empleados que tiene cada uno. De los empleados muestra todos sus atributos (e.* hace referencia a todos los campos de la tabla):
SELECT c.nom as cap, c.numemp as numcap, e.*
FROM empleats AS c JOIN empleats AS e ON c.numemp = e.cap
ORDER BY c.nom;
Debe prestarse atención en el orden en el que aparecen los campos para hacer el join, si se intercambian de este modo:
SELECT c.nom AS cap, c.numemp AS numcap, e.*
FROM empleats AS c LEFT JOIN empleats AS e ON c.cap = e.numemp
ORDER BY c.nom;
La tortilla se ha girado, el SELECT no da la misma información que antes, pues ahora los campos «e» representan los jefes:
Para obtener los jefes y sus empleados, tal y como estamos haciendo desde el principio, la siguiente consulta con LEFT JOIN no da lo buscado:
SELECT c.nom as cap, c.numemp as numcap, e.*
FROM empleats AS c LEFT JOIN empleats AS e ON c.numemp = e.cap
ORDER BY c.nom;
La que se ha solicitado aquí es tratar a todos los empleados como jefes, si lo son se mostrarán sus empleados; en el caso de ser empleados «rasos» todos los atributos de su empleado aparecen nulos, pues carecen de los mismos.
Ahora bien, esto no significa que una consulta OUTER, LEFT o RIGHT, no pueda ser útil en una relación reflexiva. Por ejemplo, si se desea un listado de todos los empleados y su jefe al lado, debe emplearse un OUTER para conseguir que también aparezcan los empleados sin jefe directo, como es el caso del director general:
SELECT e.nom as empleat, e.numemp as numempleat, c.*
FROM empleats AS e LEFT JOIN empleats AS c ON c.numemp = e.cap
ORDER BY c.nom;
En el mundo de la informática, pocas cosas más molestas hay que un disco duro pase a mejor vida, lo que además siempre será en el peor momento. El siguiente script revisa todos los discos duros instalados (externos o internos) y envía una notificación por Telegram si detecta que a uno o más de los discos le queda poco tiempo de vida. Al recibir un mensaje así, sabemos que debemos sustituir esa unidad por otra nueva, idealmente sería clonada en su reemplazo.
#!/bin/bash
BOT_TOKEN="EL TOKEN DE TU BOT"
CHAT_ID="EL ID DE TU CUENTA EN TELEGRAM"
LOG_FILE=/var/log/check_disks.log # El log se limpiará mediante logrotate.
HOSTNAME=$(hostname)
# Se añaden las rutas por si cron o anacron las necesitan
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
enviar_alerta() {
local mensaje="$HOSTNAME tiene la siguiente alerta de disco: $1"
# Enviar notificación a Telegram
curl -s -X POST "https://api.telegram.org/bot$BOT_TOKEN/sendMessage" \
-d "chat_id=$CHAT_ID" \
--data-urlencode "text=$mensaje" > /dev/null
}
# sd[a-z]: Linux no mantiene fijo el fichero del disco sino que se lo asigna en función del orden de "llegada" (orden en que "despiertan" los discos)
for disco in /dev/sd[a-z]; do
# Si no es un fichero de disco salta al siguiente dispositivo
if ! test -b "$disco" ; then
continue
fi
# El flag -n standby evita despertar al disco si está dormido, así se evita desgaste innecesario.
LSTR=$(smartctl -H -n standby "$disco" 2>&1)
# Los dormidos que sigan con Morfeo. El lector de tarjetas vacío (usb bridge) se ignora:
if echo "$LSTR" | grep -iqE "Device is in Standby|unknown usb bridge"; then
continue
fi
# Si la salud general no es PASSED, alerta al canto
if ! echo "$LSTR" | grep -qE "PASSED|OK"; then
# Extrae modelo y nº de serie del disco
IDENTIDAD=$(lsblk -d -n -o MODEL,SERIAL "$disco" | xargs)
# fallback para embellecer el mensaje en el improbable caso de que lsblk salga con un chorro de babas
if test -z "$IDENTIDAD" ; then
IDENTIDAD="desconocido"
fi
MENSAJE="El disco [$IDENTIDAD] (actualmente $disco) reporta problemas. Output: $LSTR"
enviar_alerta "$MENSAJE"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $MENSAJE" >> $LOG_FILE
fi
done
echo "[$(date '+%Y-%m-%d %H:%M:%S')] Chequeo finalizado." >> $LOG_FILE
El añadido de rutas (PATH) es para evitar posibles problemas derivados del hecho de que el cron se ejecuta en entornos muy restringidos, es decir, cuando el usuario abre una terminal tiene un PATH completo, pero un cron que arranca de forma automática en segundo plano lo hace con un PATH mínimo, que podría ser meramente «/usr/bin:/bin». En este sentido, debe tenerse en cuenta que el script debe programarse en el crontab de root o no podrá accederse a la información del disco duro:
vic@blackBox:/etc$ smartctl -H /dev/sda
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.8.0-124-generic] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
Smartctl open device: /dev/sda failed: Permission denied
El script funciona tanto para discos duros sólidos como mecánicos. Requiere tener instalados smartmontools (que proporciona smartctl) y util-linux (que proporciona lsblk). Además, tiene una feature que si para ti es un bug puedes borrarla fácilmente: Cuando un disco duro está «dormido» (en standby), lo cual es habitual en discos duros externos dedicados a las copias de seguridad, no es interrogado acerca de su estado para evitar que arranque y se desgaste innecesariamente. Como la necesidad o no de algo es relativa, depende de las circunstancias, se pueden despertar para interrogarlos eliminando el «Device is in Standby» de la orden grep del condicional. La otra cadena que busca ese grep es para evitar que el lector de tarjetas SD dé un falso positivo.
Lo mejor es programar el script para que se ejecute periódicamente mediante crontab, siendo la periodicidad semanal la ideal para todos los equipos que no sean servidores, debiendo aumentarse para estos últimos. Por cierto, si no se trata de un servidor y el equipo no está siempre encendido, como es el caso de la mayor parte de equipos domésticos, se puede programar mediante Anacron, también disponible en el ecosistema Linux / UNIX, para asegurar su ejecución semanal.
En el caso de tener el script ejecutándose en diferentes máquinas, ya sean servidores, ordenadores de la familia, de un centro educativo o de una empresa, la variable HOSTNAME nos identificará cuál de ellas tiene el disco duro desgastado.
¿Por qué Telegram?
La notificación se hace mediante Telegram simplemente por ser muy fácil su realización, pero también se podría usar una cuenta de correo (por ejemplo Gmail) en la que identificarse y enviar el correo mediante curl. La creación de un bot es muy fácil en Telegram: sólo debemos empezar con «/start» la charla con BotFather y nos guiará en el proceso:
Bot Father Telegram
Al final del proceso nos indicará el token para poder acceder a la API de nuestro bot. En la constante CHAT_ID debemos poner el identificador de nuestro usuario de Telegram, pues en realidad esta aplicación de mensajería trabaja con chats, no con usuarios. Una vez más, enviar un «/start» al bot «User Info · Get ID · idbot» nos devuelve el ID, entre otros datos.
Finalmente, aclarar que si el fichero de log se crea en /var/log/ es para delegar a logrotate, la herramienta nativa de Linux encargada de trocear, comprimir y eliminar logs antiguos, la gestión del fichero y así poder disfrutar de la filosofía Linux de «configurar y olvidar». Sólo queda configurarlo en «/etc/logrotate.d/». A modo de ejemplo, esta es mi configuración:
Crónica de una estafa en el Marketplace y la desidia de una gran superficie
Lo vivido recientemente con la compra de una placa base ASUS H81M-K en el Marketplace de Worten ha pasado de ser una simple transacción de segunda mano a un manual de lo que NUNCA debe permitir un consumidor.
1. El anzuelo: La «France» que hablaba Mandarín
El primer síntoma de alerta fue la ubicación. El vendedor, Clare02, se publicita con una sede flamante en el centro de París (Rue de Clichy). Pero la realidad logística que observé en el tracking de YunExpress reveló un periplo de 10 días por el interior de la China profunda.
Worten permite esta publicidad engañosa, donde el cliente cree comprar en la UE – con sus garantías y cercanía – para acabar recibiendo un paquete de una región con otra legislación.
2. Un socket dañado
Nada más abrir la caja, realicé una inspección de la placa base. En apariencia, estaba en buen estado hasta que observe el socket de la CPU:
Pines dañados: En el margen superior derecho del socket LGA 1150, un pin se encuentra desplazado lateralmente. Intentar montar una CPU ahí es sentenciarla a un cortocircuito inmediato.
Falso reacondicionamiento: El vendedor alardea de «30 años de experiencia» y pruebas exhaustivas, pero la placa llegó con restos de pasta térmica antigua de su anterior dueño en el marco del socket. ¿Qué clase de «profesional» ni siquiera limpia el residuo básico antes de vender una placa como testada?
3. El Gaslighting del vendedor
Al reportar el fallo, la respuesta del vendedor es de manual de estafa:
Contamos con 30 años de experiencia profesional… es imposible que cometamos errores tan básicos… el daño es claramente consecuencia de una instalación incorrecta por su parte
El truco del espejo: culpar al cliente de una manipulación que nunca existió, pues el defecto se detectó visualmente al retirar la tapa protectora y la única CPU que tengo para esa placa base es la que tengo instalada en mi ordenador personal. De hecho, esta placa base la compré como reserva para cuando falle mi actual placa base, que ya tiene 10 años de uso. El vendedor hace un intento burdo de evadir la responsabilidad sobre un producto que nunca fue verificado antes de ser enviado desde su almacén.
4. El desentendimiento de Worten
Lo más grave no es el vendedor pícaro con todas las mañas aprendidas en Shenzhen, sino la respuesta de Worten. Tras elevar la disputa, recibí un correo genérico de su soporte:
La solicitud de devolución debe ser gestionada directamente con el vendedor… Deberás esperar por las instrucciones del vendedor…
Worten se lava las manos. Actúan como meros comisionistas de un fraude, permitiendo que vendedores extracomunitarios mientan sobre su ubicación y dejando al cliente en una situación de indefensión absoluta.
Apéndice Legal: Por qué esto es inaceptable
Para los que os encontréis en una situación similar, recordad que según la Ley General para la Defensa de los Consumidores y Usuarios:
Falta de conformidad (Art. 114 y ss.): El vendedor está obligado a entregar un producto que sea conforme con el contrato. Una placa con pines doblados y restos de suciedad no es un producto conforme.
Publicidad engañosa: Anunciar una ubicación en Francia para eludir la percepción de riesgo de un envío desde China es una práctica comercial desleal.
Responsabilidad del Intermediario: Aunque Worten sea un Marketplace, tiene una responsabilidad solidaria al procesar el pago y alojar la publicidad engañosa del vendedor. No pueden derivar al cliente a una discusión a 10.000 km de distancia cuando el contrato se perfeccionó en su plataforma española.
Veredicto
Si valoráis vuestro hardware, vuestro tiempo y vuestro dinero: Aborten Worten. No son un puerto seguro, sino un puente hacia vendedores sin escrúpulos que operan fuera del radar de las garantías europeas.
Alguien o algunas personas, en algún momento de principios del siglo XX, pensó que para crear una máquina que realizara ciertos cálculos, podría ser conveniente emplear la electricidad, las puertas lógicas, usar la base 2 como sistema de numeración y el álgebra de Boole, es decir, alguien debió sentar las bases técnicas del ordenador moderno. Personalmente, siempre tuve la duda de cómo fue ese proceso. Si bien es bastante conocido que el primer diseño de un ordenador digital fue realizado por Von Neumann en los años 40 y que los ordenadores actuales se basan en el mismo, resulta evidente que entre la máquina analítica de Charles Babbage (mecánica y que operaba en base 10) y Von Neumann debieron pasar bastantes cosas.
Bastantes años atrás, leí que Von Neumann dio una respuesta afirmativa a la pregunta de si la creación de su ordenador estaba influenciada por el trabajo de Alan Turing de 1936, en el que presenta el concepto de lo que ahora se conoce como «máquina de Turing» para resolver el problema matemático de la decibilidad. No obstante, el trabajo del matemático inglés es puramente conceptual y está centrado en resolver este célebre problema de lógica matemática, y no dice nada acerca de la base física o ingenieril de una máquina de Turing.
Recientemente he podido descubrir quién fue el creador de esta parte y cómo fue ese proceso. La clave está en la tesis de máster de Claude Elwood Shannon de 1937 llamada «A symbolic analysis of relay and switching circuits«. No la conocía y resulta que está considerada «una de las tesis de máster más importantes jamás escrita». Sus 69 páginas no tienen desperdicio, me han dado las respuestas que buscaba. En primer lugar, se entiende cuál era la situación del momento: ya existían circuitos para automatizar operaciones más o menos complejas, como centralitas de telefonía o equipos de control de motores industriales. Estos circuitos se fabricaban con relés y selectores rotativos. Este vídeo describe muy bien cómo funciona un relé:
En su tesis el autor identifica dos problemas en el trabajo con estos circuitos:
El análisis de los mismos, es decir, determinar qué hace un circuito ya existente.
La síntesis: consiste en crear un circuito a partir de unos requerimientos. La solución no es única y debería encontrarse la que requiere menor número de componentes.
La solución que el autor propone para ambos problemas es representar cada circuito mediante un conjunto de ecuaciones, cuyos términos representan los relés e interruptores del circuito. Para manipular las ecuaciones, Shannon desarrolla lo que denomina un «cálculo» (calculus), y demuestra que éste es análogo al «cálculo» de lógica proposicional (hoy en día simplemente se denomina «lógica de enunciados»). A continuación, expone que el álgebra de Boole es aplicable. Esto es debido a que la lógica de enunciados tiene estructura de álgebra de Boole.
Shannon no sigue la convención actual, él emplea el 0 para representar un circuito abierto (pasa corriente) y el 1 para el circuito cerrado (no pasa corriente), esto es importante tenerlo en cuenta para entender las primeras páginas. La suma u OR lógico se consigue mediante dos contactos ubicados en línea, accionado cada uno por un relé, mientras que el producto o AND lógico mediante dos interruptores en paralelo:
El lado izquierdo del signo igual es una representación algo más «realista», mientras que el lado derecho es una abstracción simbólica.
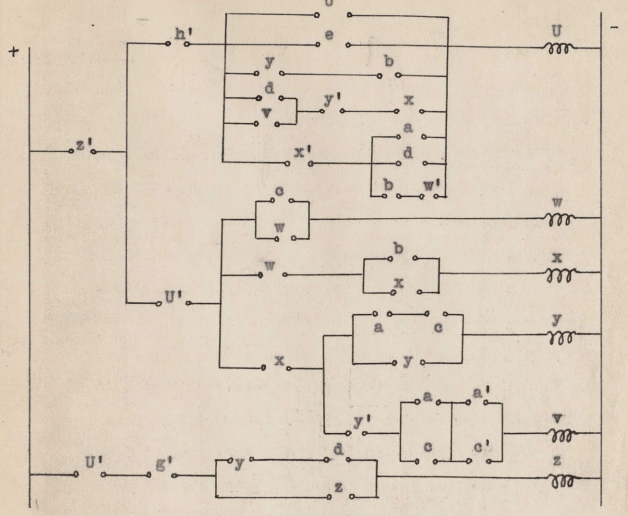
En los siguientes esquemas se representa de forma un poco más detallada cómo crear las puertas lógicas AND y OR con humildes relés:
Puerta lógica OR
Puerta lógica AND
Si bien ambos diseños se podrían simplificar para emplear un único relé, éstos son de una mayor claridad. Por cierto, la puerta lógica NOT se puede implementar con un relé inverso (en el vídeo también se explica en qué consiste este relé).
En su tesis, después de desarrollar los conceptos básicos, explicar la analogía con la lógica de enunciados, mostrar los teoremas de álgebra de Boole que serán útiles para la síntesis de circuitos y poner ejemplos prácticos de su aplicación, en las páginas 16 / 17 hace una afirmación que parece avanzada a su tiempo:
También es posible emplear la analogía entre el álgebra de Boole y los circuitos de relés en dirección contraria, es decir, representar relaciones lógicas mediante circuitos eléctricos. Siguiendo esta línea se han obtenido algunos resultados interesantes, pero no son de importancia aquí.
Al decir que los circuitos pueden hacer cálculos lógicos, ha concebido el ordenador digital moderno. Su afirmación de que esto carece de importancia en su tesis no sé si es por modestia o porque no intuye sus disruptivas aplicaciones futuras. Al final de su tesis muestra el diseño de dos máquinas: una es un «sumador eléctrico» (electric adder) que trabaja en base 2 y la otra da todos los múltiplos de todos los primos menores o iguales a 10.000, a partir de la cual un humano sabrá que cualquier número inferior a 100.000.000 que no esté en la lista obtenida es un número primo (aunque la del diagrama de ejemplo está limitada a los tres primeros primos). Hasta el momento, hacer una lista así manualmente había representado un gran esfuerzo y encima con algunos errores, como Shannon explica. Si bien estas máquinas parecen ordenadores primitivos, todavía les falta una memoria programable, además de carecer de condicionales y saltos.
Ecuaciones del sumador eléctrico
Diseño del sumador eléctrico
En definitiva, esta tesis sentó las bases para la creación de circuitos digitales (y por lo tanto de los ordenadores) con una base teórica sólida, a diferencia de cómo se diseñaban los circuitos en esa época y mucho antes de la invención del transistor. Si bien este no es el trabajo más famoso de Claude Elwood Shannon, fue fundamental para sentar las bases del fenómeno que más ha cambiado la existencia del ser humano durante la segunda mitad del siglo pasado y del actual. En lo personal, descubrirlo ha sido encontrar mi eslabón perdido entre por un lado Babbage y por el otro Von Neumann y la tesis de Church-Turing.
Históricamente, los lenguajes siempre se habían dividido entre interpretados y compilados, en lo que se refiere a su ejecución. A día de hoy, con los compiladores JIT se crea una nueva categoría: los lenguajes que son una combinación de ambos. Los compiladores JIT son omnipresentes, por ejemplo los navegadores modernos disponen de uno para el lenguaje Javascript. También las máquinas virtuales de Java han evolucionado para incluir esta técnica, y es el caso concreto en el que se va a profundizar en este artículo.
Las implementaciones modernas de Java emplean un proceso de compilación dividido en dos pasos en el cual se produce una compilación en tiempo de ejecución, es decir, las máquinas virtuales de Java actuales disponen de un compilador JIT, just-in-time por sus siglas en inglés. En primer lugar, el compilador de Java compila en bytecode el código fuente, este bytecode es independiente de la plataforma de hardware donde se ejecuta. La máquina virtual de Java (JVM) es la encargada de ejecutar (interpretar mediante un intérprete) este bytecode. La máquina virtual sí es dependiente de la plataforma: Cada plataforma requiere de su propia máquina virtual para poder ejecutar el bytecode.
El compilador JIT de la máquina virtual es el encargado de detectar partes de este bytecode que se están ejecutando con mucha frecuencia y compilarlas al código máquina de la CPU de la plataforma para aumentar la velocidad de ejecución. El componente del compilador JIT encargado de detectar estos «puntos calientes» («hotspots» o «hot code» en inglés) del código es el profiler. Además, lo realiza en tiempo de ejecución, es decir, a medida que el programa se está ejecutando, detecta cuáles nuevas partes del código se han calentado y cuáles se han enfriado. De esta manera se supera la principal ineficiencia de los intérpretes: cuando código que se está ejecutando de forma reiterada (por ejemplo debido a un bucle while / for) debe ser interpretado una y otra vez. Además, esta característica es realmente potente, pues consigue que determinados tipos de programas se ejecuten más rápido que su equivalente en un lenguaje compilado orientado a objetos.
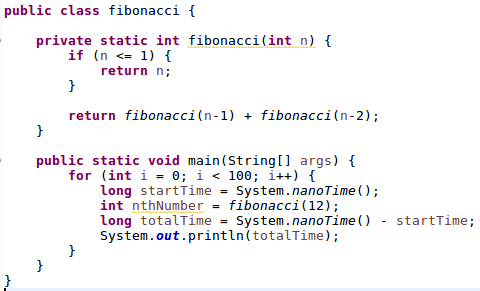
Para ver un caso concreto de cómo se optimiza en tiempo de ejecución un programa realizado en Java, pongamos a trabajar al ordenador: calculará 100 veces el número situado en la duodécima posición de la serie de Fibonacci, una forma como otra cualquiera de poner a calcular un ordenador. Este número es el 144, pero lo que realmente nos interesa es el tiempo transcurrido en cada una de las 100 ejecuciones.


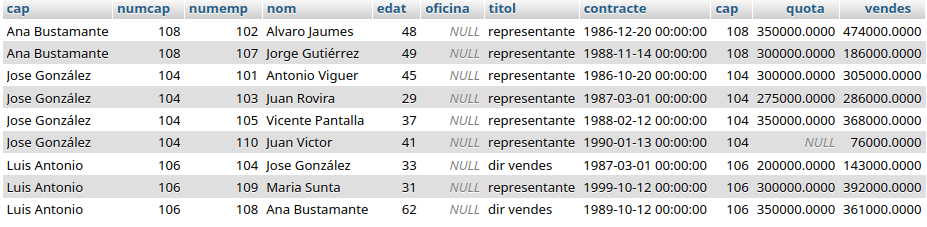 Debe prestarse atención en el orden en el que aparecen los campos para hacer el join, si se intercambian de este modo:
Debe prestarse atención en el orden en el que aparecen los campos para hacer el join, si se intercambian de este modo: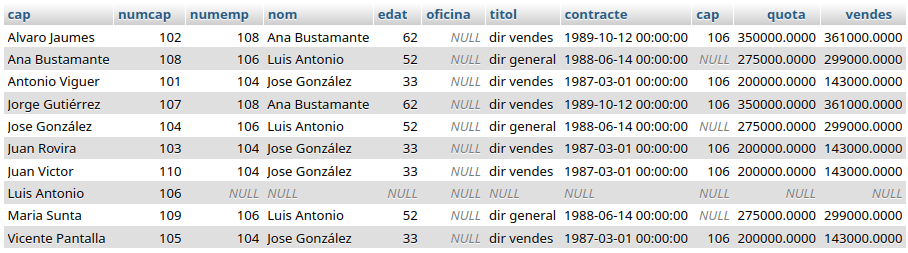
 La que se ha solicitado aquí es tratar a todos los empleados como jefes, si lo son se mostrarán sus empleados; en el caso de ser empleados «rasos» todos los atributos de su empleado aparecen nulos, pues carecen de los mismos.
La que se ha solicitado aquí es tratar a todos los empleados como jefes, si lo son se mostrarán sus empleados; en el caso de ser empleados «rasos» todos los atributos de su empleado aparecen nulos, pues carecen de los mismos.